Home » Inteligencia artificial
Category Archives: Inteligencia artificial
A qué se hace referencia cuando hablamos de digitalización, inteligencia artificial y algoritmos
¿A qué se hace referencia cuando hablamos de digitalización, inteligencia artificial y algoritmos?
Faraón Llorens Largo y Rafael Molina Carmona
Capítulo I
Páginas 21-40
En:
Trabajo y digitalización: avances y retos para el diálogo social y la negociación colectiva
Carolina Blasco Jover (directora)
Práctica Jurídica
Editorial Tecnos
www.tecnos.es

Sumario del capítulo:
Resumen.
I. El sueño de la automatización.
1. Inteligencia artificial.
2. La era del algoritmo.
3. Sistemas de propósito general.
Recapitulando.
II. La transformación digital.
1. Digitalización.
2. Madurez digital.
Recapitulando.
III. Algunas reflexiones para el mundo del trabajo.
IV. Algunas reflexiones para el mundo de la educación.
V. Gobernando la inteligencia artificial.
Referencias bibliográficas.
Resumen del capítulo:
Cuando un término se pone de moda y todos hablan de él, se corre el riesgo (más bien la certeza) de que será malinterpretado, usado con ligereza o, incluso, con intereses partidistas. El objetivo de este capítulo introductorio es aclarar los conceptos de digitalización, transformación digital, inteligencia artificial y algoritmo. Se han simplificado al máximo los conceptos y su explicación, así como evitado caer en jerga técnica en aras de su comprensión, para que, una vez entendidos, se pueda profundizar en los detalles, que es donde residen las claves para un buen uso de la tecnología. Más aún de unas tecnologías que pueden ser disruptivas como es el caso de la inteligencia artificial. Hemos optado por poner todos los términos en castellano, pero mantener entre paréntesis los términos originales en inglés, ya que son conceptos que no debemos confundir con el significado general que se le puede dar a la palabra en castellano.
Este trabajo se estructura en cinco secciones que abordan aspectos clave de la revolución digital. En la primera sección se explora la evolución de la inteligencia artificial desde sus inicios hasta su aplicación actual, analizando la omnipresencia de los algoritmos. La segunda sección examina la diferencia entre digitalización y transformación digital, así como la importancia de la madurez digital en las organizaciones. Las dos siguientes secciones reflexionan sobre el impacto de la inteligencia artificial en el mundo laboral y educativo, destacando la necesidad de adaptación y actualización de habilidades. Finalmente, se abordan cuestiones de gobernanza en este ámbito en constante evolución. Creemos que este enfoque integral proporciona una visión completa de la intersección entre la tecnología y la sociedad.
Repassant un any d’IA; repensant un món amb IA
Repassant un any d’IA
repensant un món amb IA
Faraón Llorens Largo
4 d’abril de 2024
Jornada La intel·ligència artificial i la docència UVic-UCC
Universitat de Vic – Universitat Central de Catalunya
https://www.uvic.cat






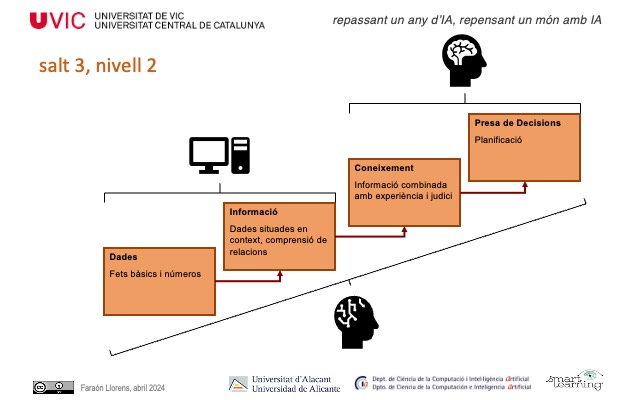
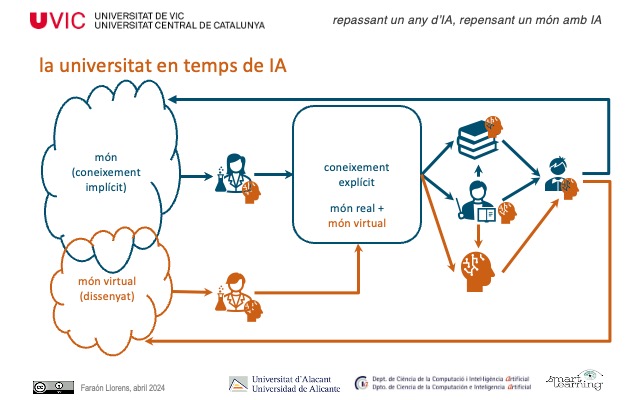


Enlaces noticias:
El Vicerectorat d’Ordenació Acadèmica i la UDUTE organitzen una jornada sobre intel·ligència artificial per a PDI i PAS (L’apunt. Revista digital de la UVic) (14/03/2024)
https://apunt.uvic.cat/el-vicerectorat-dordenacio-academica-i-la-udute-organitzen-una-jornada-sobre-intelligencia
Un centenar de persones assisteixen a la jornada La Intel·ligència Artificial i la Docència UVic-UCC (L’apunt. Revista digital de la UVic) (04/04/2024)
https://apunt.uvic.cat/un-centenar-de-persones-assisteixen-a-la-jornada-la-intelligencia-artificial-i-la-docencia-uvic-ucc
Inteligencia artificial. Guía para seres pensantes
Inteligencia artificial.
Guía para seres pensantes
Melanie Mitchell
Capitán Swing (capitanswing.com)
https://capitanswing.com/libros/inteligencia-artificial

Frases entresacadas e ideas interesantes que puedo utilizar:
(Página )
“”
Las nuevas leyes de la robótica
Las nuevas leyes de la robótica.
Defender la experiencia humana en la era de la IA
Frank Pasquale
Galaxia Gutenberg
www.galaxiagutenberg.com

Frases entresacadas e ideas interesantes que puedo utilizar:
Leyes de la robótica de Asimov:
1. Un robot no hará daño a un ser humano ni, por inacción, permitirá que un ser humano sufra daño.
2. Un robot debe cumplir las órdenes dadas por los seres humanos, a excepción de aquellas que entren en conflicto con la primera ley.
3. Un robot debe proteger su propia existencia en la medida en que esta protección no entre en conflicto con la primera o con la segunda ley.
Nuevas leyes de la robótica:
1. Los sistemas robóticos y de IA deberán servir de complemento a los profesionales, no reemplazarlos.
2. Los sistemas robóticos o la IA no tienen que falsificar lo humano.
3. Los sistemas robóticos y la IA no deben fomentar la carrera armamentística de suma cero.
4. Los sistemas robóticos y la IA tienen que indicar siempre la identidad de su(s) creador(es), controlador(es) y propietario(s).
Capítulo completo Más allá del aprendizaje de las máquinas (99-134)
(Página 102)
“Para dejar claras las cosas: tenemos que decidir si vamos a invertir en una IA educativa que no deje en ningún momento de medir y evaluar a los estudiantes o vamos a centrar nuestras energías en productos que favorezcan el avance del aprendizaje mediante el apoyo y al creatividad.”
“La educación tiene múltiples propósitos y objetivos, muchos de los cuales no pueden o no deberían poder ser reducidos a una cuantificación numérica. Si permitimos que la IA nos obligue a apartar nuestra atención del aprendizaje actual y a centrarnos en aquello que pueda ser medido y optimizado por ordenadores, habremos perdido una enorme oportunidad. Peor aún, habremos permitido que la tecnología usurpe y, en última instancia, dicte nuestros valores en lugar de servir como herramienta para asumirlos.”
(Página 140)
“Las principales empresas tienen que responsabilizarse de lo que priorizan o publican. No pueden seguir culpando al “algoritmo” por la difusión de información lesiva y la incitación. Podemos exigir valores humanos a la inteligencia artificial o bien sufrir las consecuencias de que cultive entre nosotros la inhumanidad. No hay término medio.”
(Página 173)
“La discriminación es un peligro presente y obvio. El software puede excluir minorías que no están representadas en las bases de datos de la IA.
/…/
Si las mujeres no formaron parte de los equipos directivos en el pasado, no pueden formar parte de las bases de datos que predicen las estrellas del futuro.”
(Página 317)
“Generan palabras según bases de datos de palabras; imágenes, según bases de datos de imágenes; pero se quedan aislados como náufragos en un océano silencioso de correlaciones, despojados de la experiencia sensorial que subyace a nuestro entendimiento intuitivo de realidades y relaciones.”
MANIAC
MANIAC
Benjamín Labatut
Editorial ANAGRAMA
https://www.anagrama-ed.es/libro/narrativas-hispanicas/maniac/9788433911001/NH_723

Frases entresacadas e ideas interesantes que puedo utilizar:
(Página 115)
“Al combinar las ideas de Gödel y von Neumann, el resultado desafiaba la lógica. Desde entonces hasta la eternidad, los matemáticos tendrían que elegir entre dos escenarios: o se resignaban a convivir con paradojas y contradicciones, o debían aceptar verdades que no podían probar.”
(Página 214)
“Turing aprendió algo fundamental al observar a sus “niños”: para que las máquinas llegasen algún día a avanzar hacia la verdadera inteligencia, tendrían que ser falibles; capaces no solo de cometer errores y salirse de su programación original, sino también de tener comportamientos ilógicos y absurdos. Turing creía que el azar y la aleatoriedad jugarían un rol crucial en las máquinas inteligentes, porque permiten respuestas nuevas e impredecibles, creando una gran variedad de posibilidades, entre las cuales un programa de búsqueda podría encontrar la acción apropiada para cada circunstancia en particular.”
Explorando el futuro educativo con la Inteligencia Artificial
Explorando el futuro educativo con la Inteligencia Artificial
Por Ángel Fidalgo el 19 diciembre 2023
https://innovacioneducativa.wordpress.com/2023/12/19/explorando-el-futuro-educativo-con-la-inteligencia-artificial
Se comparte las conferencias y talleres sobre Inteligencia Artificial en la Educación realizadas en el marco del congreso CINAIC, celebrado el pasado mes de octubre.
Taller práctico “ChatGPT y Moodle ¿sirve esa unión para mi docencia?”
Conferencia colaborativa e interactiva sobre Inteligencia Artificial “¡Qué viene la IA! ¿estoy preparada/o?
Análisis oportunidades y riesgos de la aplicación de la IA en la educación. Discusión abierta.
Ya llegó, ya está aquí, y nadie puede esconderse: La inteligencia artificial generativa en educación
Ya llegó, ya está aquí, y nadie puede esconderse: La inteligencia artificial generativa en educación.
Faraón Llorens-Largo (Universidad de Alicante), Javier Vidal (Universidad de León) y Francisco José García-Peñalvo (Universidad de Salamanca)
Aula Magna 2.0 [Blog].
Revistas Científicas de Educación en Red.
https://cuedespyd.hypotheses.org
ISSN: 2386-6705
8 diciembre 2023
https://cuedespyd.hypotheses.org/14389
Palabras clave: RIED, inteligencia artificial, inteligencia artificial generativa, ChatGPT, educación
Educación e Inteligencia Artificial
La investigación en Inteligencia Artificial (IA) lleva años en continuo crecimiento y no muestra signos de desaceleración. Se están desarrollando modelos más complejos, más grandes y de respuesta más rápida. Estos modelos se entrenan con grandes cantidades de datos, lo que los hace mucho más potentes que sus antecesores de no hace tantos años. Esta potencia le dota de una amplia gama de aplicaciones, incluso algunas de ética cuestionable, dando lugar a vacíos legales y a reacciones extremas que llegan hasta la prohibición de su uso.
/…/
Los problemas que aquí hemos presentado no son solo propios del ámbito de la educación, también afectan a otros sectores. Afectará a toda aquella tarea que requiera el manejo rápido de grandes cantidades de información contenida en bases de datos o, y esta es la gran novedad, en textos. La educación no debe situarse al margen de estos debates y debemos imponernos la tarea de estar atentos a las opciones que estas herramientas nos dan para maximizar las posibilidades de aprendizaje de todos: profesorado y estudiantado. Quizás debamos realizar ciertos cambios en los planes de estudio de nuestras titulaciones incorporando el aprendizaje del uso de estas herramientas en cada uno de los campos, pero lo que es seguro es que tendremos que hacer, sin más demora, cambios sustanciales en nuestra manera de enseñar y en lo que pediremos a nuestro estudiantado que haga, porque no es la inteligencia artificial la que va a decidir lo que hacen los humanos, sino los humanos los que deben tomar decisiones con la ayuda de la inteligencia artificial (Marina, 2020).
La inteligencia artificial en el gobierno universitario
La inteligencia artificial en el gobierno universitario
UniverSÍdad (www.universidadsi.es)
Faraón Llorens y Francisco J. García Peñalvo
05/12/2023
Llevamos un año en el que la inteligencia artificial (IA) ha saltado al debate público debido al lanzamiento el último día de noviembre de 2022 de ChatGPT, que ha roto todos los récords de penetración. Y las universidades, como era de esperar no han sido ajenas a esta vorágine. Tanto los máximos responsables universitarios como el profesorado han estado pendientes del tema y debatiendo sobre su posible impacto en sus instituciones y en su labor docente.
La rápida evolución de la IA, especialmente con la llegada de la IA generativa, requiere un enfoque estratégico de gobernanza en las instituciones de educación superior.
Aunque en el ámbito de la gobernanza universitaria hemos visto una preocupación creciente y una actitud proactiva, publicándose numerosas guías y recomendaciones para el uso de la IA generativa en la docencia, aun no existen políticas institucionales al respecto.
/…/
Liderando la universidad del futuro
Las dificultades y riesgos de la IA no deben parar su implantación y utilización en nuestras universidades en aquellas tareas en las que proporcione soluciones más eficientes y personalizadas. Debemos ser conocedores de estos y tomar las medidas oportunas para paliar los posibles efectos negativos.
Con esta entrada, queremos enfatizar la gobernanza estratégica de la IA y presentar un enfoque integral para las instituciones de educación superior. Pero también queremos subrayar la importancia de abrazar la IA, no como una herramienta tecnológica aislada, sino como una parte integral del viaje transformador de una institución.
La IA debería entrelazarse con la gobernanza de las TI y su estrategia de transformación digital.
Que la IA forme parte del gobierno universitario es necesario para establecer el escenario en el que las universidades sigan liderando una época que se verá impulsada por esta herramienta. Con la IA hay que asegurar que las instituciones permanezcan a la vanguardia de la innovación educativa al tiempo que salvaguardan sus principios fundamentales.
Leer la entrada completa:
www.universidadsi.es/la-inteligencia-artificial-en-el-gobierno-universitario/
Bailando con la IA en una baldosa
Bailando con la IA en una baldosa
Cuestiones básicas sobre la Inteligencia Artificial
Faraón Llorens
Jornadas sobre Derecho de la Inteligencia Artificial
4 y 5 de diciembre de 2023
Sala de Juicios de la Facultad de Derecho
Universidad de Alicante
Organiza: CEUA (Consejo de Estudiantes de la Universidad de Alicante)

Programa:





IA para las personas
La Inteligencia Artificial para la personalización del aprendizaje
Rafael Molina, Alberto Real y Faraón Llorens
Explorando las posibilidades de ChatGPT en los trabajos de los estudiantes
Faraón Llorens, Sergio Arjona y Rafael Molina
Jornada IA para las personas
14 de noviembre de 2023
Cátedra Interuniversitaria SISTEMA PÚBLICO VALENCIANO DE SERVICIOS SOCIALES
Organiza: Centro de Investigación Operativa
Universidad Miguel Hernández