Introducción
Hace unos días tuve una conversación muy recurrente entre desarrolladores de software respecto del uso cotidiano de SQL. ¿Cómo usar JOIN? Esta duda la tienen aún desarrolladores expertos, pues bien vamos a aclarar un poco que es eso del JOIN.
Como breve resumen, decir que JOIN se usa en SQL para combinar filas de dos o más tablas. Y es una sentencia con tantas posibilidades que realmente se merece una explicación en una única entrada de este blog.
La sentencia JOIN como una expresión algebraica
Si tomamos cada tabla de la base de datos como un conjunto de datos donde cada columna posee su propio dominio definimos el operador  como el JOIN para el conjunto de tuplas a relacionar (no deja de ser una composición):
como el JOIN para el conjunto de tuplas a relacionar (no deja de ser una composición):
\})
De modo que R y S son dos tablas, y t y s son filas de cada tabla que se unirán si se cumple la condición dada. Y lo más fácil es ver el siguiente dibujo que representa los diferentes tipos de JOINS que existen conceptualmente (no todas los sistemas gestores de base de datos los soportan) y su representación aproximada como diagrama de Venn:
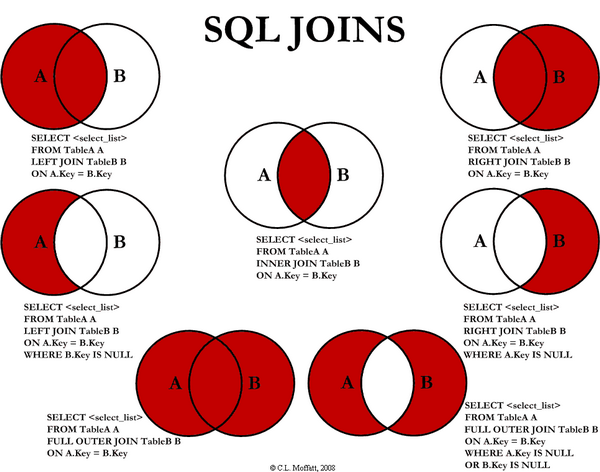
En este dibujo podemos ver gráficamente la idea de cada tipo de JOIN, filas que se relacionan en ambas tablas (conjuntos), filas que no tengan relación y estén en una tabla pero sí en la otra. O al revés, filas que no estén en la primera tabla y sí en la segundo, y en fin … todas las combinaciones que muestra el gráfico.
Por cierto, si se hace una composición de dos tablas con JOIN y la fila compuesta devuelta es resultado de una relación donde para una tabla hay datos y en la segunda tabla no existe relación, los campos de esa segunda tabla devueltos serám NULL.
Para leer más sobre algebra relacional recomiendo los apuntes de Pedro Pablo Alarcón Cavero [4], buen material docente sin duda. Pero todo esto es mejor analizarlo con un buen ejemplo.
Caso práctico
Si accedemos a la Web de W3Schools, tiene una base de datos de ejemplo donde podemos probar online difernetes sentencias SQL [Acceso a la BD en W3Schools].
Tablas de datos básicas
En este apartado primero vamos a ver una muestra de los datos que contienen las tablas, en la mayoría de casos vamos a ver una SELECT y los primeros registros que devuelve la base de datos, para mas información consultar el enlace “Acceso a la DB de W3Schools”.
Listado de Clientes
select * from Customers
| CustomerID |
CustomerName |
ContactName |
Address |
City |
PostalCode |
Country |
| 1 |
Alfreds Futterkiste |
Maria Anders |
Obere Str. 57 |
Berlin |
12209 |
Germany |
| 2 |
Ana Trujillo Emparedados y helados |
Ana Trujillo |
Avda. de la Constitución 2222 |
México D.F. |
05021 |
Mexico |
| 3 |
Antonio Moreno Taquería |
Antonio Moreno |
Mataderos 2312 |
México D.F. |
05023 |
Mexico |
(Devuelve 91 clientes)
Listado de Empleados
select * from Employees
| EmployeeID |
LastName |
FirstName |
BirthDate |
Photo |
Notes |
| 1 |
Davolio |
Nancy |
1968-12-08 |
EmpID1.pic |
Education includes a BA in psychology from Colorado State University. She also completed (The Art of the Cold Call). Nancy is a member of ‘Toastmasters International’. |
| 2 |
Fuller |
Andrew |
1952-02-19 |
EmpID2.pic |
Andrew received his BTS commercial and a Ph.D. in international marketing from the University of Dallas. He is fluent in French and Italian and reads German. He joined the company as a sales representative, was promoted to sales manager and was then named vice president of sales. Andrew is a member of the Sales Management Roundtable, the Seattle Chamber of Commerce, and the Pacific Rim Importers Association. |
(Devuelve 10 empleados)
Listado de Transportistas
select * from Shippers
| ShipperID |
ShipperName |
Phone |
| 1 |
Speedy Express |
(503) 555-9831 |
| 2 |
United Package |
(503) 555-3199 |
| 3 |
Federal Shipping |
(503) 555-9931 |
(Devuelve 3 transportistas)
Listado de Pedidos
select * from Orders
| OrderID |
CustomerID |
EmployeeID |
OrderDate |
ShipperID |
| 10248 |
90 |
5 |
1996-07-04 |
3 |
| 10249 |
81 |
6 |
1996-07-05 |
1 |
| 10250 |
34 |
4 |
1996-07-08 |
2 |
(Devuelve 196 pedidos)
Obtener los pedidos de cada cliente
Este es el ejemplo que ofrece W3SChools:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers
ON Orders.CustomerID=Customers.CustomerID;
| OrderID |
CustomerName |
OrderDate |
| 10248 |
Wilman Kala |
1996-07-04 |
| 10249 |
Tradição Hipermercados |
1996-07-05 |
| 10250 |
Hanari Carnes |
1996-07-08 |
| 10251 |
Victuailles en stock |
1996-07-08 |
(Mostramos los 4 primeros, hay 196 resultados)
Obtener los clientes que nunca han hecho un pedido
Ahora vamos a pensar en la tabla clientes y en pedidos. En pedidos se registran los pedidos y qué cliente lo realiza, pero … ¿cómo saber qué clientes no han hecho aún un pedido?
SELECT c.CustomerID AS CodigoCliente, c.CustomerName, o.CustomerID AS ClienteEnPedido
FROM Customers AS c
LEFT JOIN Orders AS o ON c.CustomerID=o.CustomerID
WHERE o.OrderID IS NULL;
| CodigoCliente |
CustomerName |
ClienteEnPedido |
| 1 |
Alfreds Futterkiste |
null |
| 6 |
Blauer See Delikatessen |
null |
| 12 |
Cactus Comidas para llevar |
null |
| 22 |
FISSA Fabrica Inter. Salchichas S.A. |
null |
| 26 |
France restauration |
null |
| 32 |
Great Lakes Food Market |
null |
| 40 |
La corne d’abondance |
null |
| 42 |
Laughing Bacchus Wine Cellars |
null |
| 43 |
Lazy K Kountry Store |
null |
| 45 |
Let’s Stop N Shop |
null |
| 50 |
Maison Dewey |
null |
| 53 |
North/South |
null |
| 57 |
Paris spécialités |
null |
| 64 |
Rancho grande |
null |
| 74 |
Spécialités du monde |
null |
| 78 |
The Cracker Box |
null |
| 82 |
Trail’s Head Gourmet Provisioners |
null |
De los 91 clientes que hay, estos 17 no tiene pedidos realizados. Además podemos ver cómo la columna con el ID de cliente en pedidos obtenida con este JOIN vale NULL, con lo que sabemos que existe relación.
Obtener los empleados que no han hecho ventas
Este es otro ejemplo cómo el anterior:
SELECT e.EmployeeID, e.FirstName
FROM Employees AS e
LEFT JOIN Orders AS o ON e.EmployeeID=o.EmployeeID
WHERE o.EmployeeID IS NULL;
| EmployeeID |
LastName |
FirstName |
BirthDate |
Photo |
Notes |
| 10 |
West |
Adam |
1928-09-19 |
EmpID10.pic |
An old chum. |
Adam West es el único cliente que no ha registrado pedidos en la base de datos.
Obtener qué pedidos ha hecho Nancy
Este caso es el mismo que obtener los pedidos de cada cliente, pero añadiendo un flltro por empleado.
SELECT e.EmployeeID, e.FirstName, o.OrderID
FROM Employees AS e
INNER JOIN Orders AS o ON e.EmployeeID=o.EmployeeID
WHERE e.FirstName = 'Nancy';
| EmployeeID |
FirstName |
OrderID |
| 1 |
Nancy |
10258 |
| 1 |
Nancy |
10270 |
| 1 |
Nancy |
10275 |
| 1 |
Nancy |
10285 |
| 1 |
Nancy |
10292 |
Muestro los 5 primeros pedidos, pero Nancy ha hecho 29 pedidos.
Conclusión
JOIN es una clausula para las consultas SELECT que enrique mucho el lenguaje SQL, permite realizar consultas para diferentes casos muy interesantes sin tener que recurrir a escribir consultas muy complicadas.
Ejemplos para analizar el uso de JOIN hay muchos y en Google podemos encontrar muchos, espero que este resumen sirva de ayuda.
Referencias
- Join en Wikipedia: http://es.wikipedia.org/wiki/Join
- Join en W3SChools: http://www.w3schools.com/sql/sql_join.asp
- Manual de MySQL5 – Sentencia JOIN: http://dev.mysql.com/doc/refman/5.0/es/join.html
- Para leer algo más sobre algebra relacional (con permiso de Pedro Pablo Alarcón Cavero ): http://www-oei.eui.upm.es/Asignaturas/BD/BD/docbd/tema/algebra.pdf