¿El problema? Tenemos una hoja excel con una columna numérica cuyo valor es 0 pero queremos no mostrar el valor cuando es 0, por ejemplo para una formula. como en el siguiente caso:
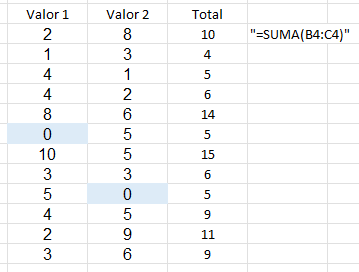

¿El problema? Tenemos una hoja excel con una columna numérica cuyo valor es 0 pero queremos no mostrar el valor cuando es 0, por ejemplo para una formula. como en el siguiente caso:
Recientemente he tenido que reinstalar mi equipo de trabajo, y comprobando que la nueva instalación funcionaba como la anterior me he encontrado que al recompilar un proyecto hecho con .NET5 no compilaba (le falta encontrar los origenes de Nuget), dando el siguiente mensaje:
Mule es ESB (Enterprise Service Bus) Se usa para enviar/recibir mensajes heterogéneos entre diferentes productos/consumidores.
Admite muchos componentes de transporte y servicio como JMS, SOAP, JBI, BPEL, EJB, AS/400, HTTP, JDBC, TCP, UDP, SMTP, FILE, FTP y más.
Como en Internet el idioma padre es HTTP vamos a ver cómo hacer logging de las peticiones y respuestas HTTP que pasan por mule.
La instrucción using:
using(var disposableObject = new object_that_implements_IDisposable()) { ... }
es una construcción usada para ahorra código al usar una estructura que implemente IDisposable cómo esta:
var disposableObject = new object_that_implements_IDisposable()
try
{
...
}
finally
{
if(disposableObject != null)
{
((IDisposable)your_object).Dispose();
}
}
Esta instrucción sólo tiene sentido para declarar objetos que implementen el interfaz IDisposable
Referencia: using (Instrucción, Referencia de C#)
Cuando manipulamos documentos XML [1] desde PHP [2] uno de los “quebraderos” de cabeza son los namespaces. Un namespace no es nada complicado ni rocambolesco como algunos opinan; no deja de ser un enriquecimiento semántico para dotar de más información a un documento XML.
Tradicionalmente los desarrolaldores PHP no se han complicado con este concepto. Pero hoy en día con la cantidad de mensajes y documentos XML que envían mediante REST, SOAP, APIs de terceros, etc. es inevitable y totalmente recomendable conocer como manipularlos de forma sencilla en PHP.
Por lo general cualquier documento XML generado por y para Google tendrá en namespace http://base.google.com/ns/1.0, que simplemente añade algo de información adicional al documento XML (descripciones, items, ….) [4].
Cómo ejemplo vamos a manipular un documento para el servicio Google Shopping [3].
<?xml version="1.0"?>
<rss version="2.0" xmlns:g="http://base.google.com/ns/1.0">
<channel>
<title>El nombre de tu feed de datos</title>
<link>http://www.example.com</link>
<description>Una descripción de tu contenido</description>
<item>
<title>Suéter de lana rojo</title>
<link> http://www.example.com/página-información-producto1.html</link>
<description>Suéter suave y cómodo que te abrigará en las frías noches de
invierno</description>
<g:image_link>http://www.example.com/imagen1.jpg</g:image_link>
<g:price>25</g:price>
<g:condition>nuevo</g:condition>
<g:id>1a</g:id>
</item>
</channel>
</rss>
Si leyéramos este documento directamente con SimpleXML no entendería los namespaces ni sus elementos, quedan este documento:
<?xml version="1.0"?>
<rss version="2.0" xmlns:g="http://base.google.com/ns/1.0">
<channel>
<title>El nombre de tu feed de datos</title>
<link>http://www.example.com</link>
<description>Una descripción de tu contenido</description>
<item>
<title>Suéter de lana rojo</title>
<link> http://www.example.com/página-información-producto1.html</link>
<description>Suéter suave y cómodo que te abrigará en las frías noches de
invierno</description>
</item>
</channel>
</rss>
¿Cómo solucionarlo? Un ejemplo tonto sería la siguiente función que dado un elemento de un documento XML con SimpleXML busca los elementos del namespace http://base.google.com/ns/1.0. Obtenidos los elementos de este namespace en ese nodo, sólo debemos recoger la propiedad deseada (precio).
function xml_get_price(SimpleXMLElement $item)
{
$googleSpace = $item->children('http://base.google.com/ns/1.0');
return $googleSpace->price; // para el ejemplo anterior: 25
}
¡Fin! Espero que sea útil.
En un proyecto reciente he tenido que preparar un sistema de reservas para un hotel. La idea es sencilla poder reservar recursos (en este caso habitaciones) entre unas fechas determinadas.
Pero además, como es un hotel se da una condición especial. La fecha de inicio y de fin no son cerradas, quiero decir que una reserva puede terminar el mismo día que otra empieza y viceversa. Por todos es sabido, que normalmente en un hotel la hora de salida es hasta las 12:00am y la hora de entrada es a partir de las 14:00pm.
¿Cómo resolverlo? Sencillo,veamoslo.
Primero suponemos un esquema tan sencillo como el siguiente:
CREATE SCHEMA IF NOT EXISTS `mydb` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci ;
CREATE TABLE IF NOT EXISTS `mydb`.`habitaciones` (
`numero` INT(11) NOT NULL,
`nombre` VARCHAR(45) NULL DEFAULT NULL,
`camas` INT(11) NULL DEFAULT NULL,
`camagrande` TINYINT(1) NULL DEFAULT NULL,
`disponible` TINYINT(1) NULL DEFAULT NULL,
PRIMARY KEY (`numero`))
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8
COLLATE = utf8_general_ci;
CREATE TABLE IF NOT EXISTS `mydb`.`reservas` (
`reserva_id` INT(11) NOT NULL AUTO_INCREMENT,
`habitaciones_numero` INT(11) NOT NULL,
`entrada` DATE NULL DEFAULT NULL,
`salida` DATE NULL DEFAULT NULL,
`nombrecliente` VARCHAR(45) NULL DEFAULT NULL,
`telefono` VARCHAR(45) NULL DEFAULT NULL,
PRIMARY KEY (`reserva_id`),
INDEX `fk_reservas_habitaciones_idx` (`habitaciones_numero` ASC),
CONSTRAINT `fk_reservas_habitaciones`
FOREIGN KEY (`habitaciones_numero`)
REFERENCES `mydb`.`habitaciones` (`numero`)
ON DELETE NO ACTION
ON UPDATE NO ACTION)
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8
COLLATE = utf8_general_ci;
El siguiente paso paso sería crear algún dato. Una vez hecho esto, podemos considerar muchos casos posbles, buscando en Internet seguro que hay muchas aproximaciones pero la solución final que yo he encontrado y funciona perfectamente para mi caso es la siguiente:
set @dstart = date_add('2014-03-15', interval 1 day);
set @dend = date_sub('2014-04-01', interval 1 day);
select id, vivienda_id, arrival_date, departure_date, date_add(@dstart, interval 1 day) firstday, date_sub(@dend, interval 1 day) lastday
from espana_reservations r
where (arrival_date between @dstart and @dend)
or (@dstart between arrival_date and departure_date)
Espero que haya sido de ayuda!
Como desarrollador Web en alguna ocasión he tenido que realizar algún proyecto sin disponibilidad de tener un servidor de desarrollo. Hasta este punto, existen tres opciones si queremos trabajar con un servidor de desarrollo en lugar de usar un WAMP o un XAMPP (que son cómodos pero poco profesionales).
En esta entrada me voy a decantar por esta última opción por comodidad y rapidez. Pero hay que tener en cuenta que esta solución sólo servirá para tener un entorno multihost para uno mismo, si se trabaja en grupo en un red no será un sistema válido.
Lo primero, es instalar un sistema LAMP (Linux, Apache, Mysql, PHP). Esto en un sistema Debian/Ubuntu es tan sencillo cómo ejecutar en consola:
$ sudo apt-get install apache2 apache2-mpm-worker apache2-utils apache2.2-bin apache2.2-common libaprutil1-dbd-sqlite3 libaprutil1-ldap libhtml-template-perl mysql-server mysql-server-5.5 mysql-server-core-5.5 apache2-mpm-prefork libapache2-mod-php5 libtidy-0.99-0 php5 php5-cli php5-common php5-curl php5-gd php5-mysql php5-odbc php5-sqlite php5-tidy php5-xdebug php5-xmlrpc libapache2-mod-auth-mysql libphp-jpgraph dbconfig-common libmcrypt4 php-doc php5-mcrypt phpmyadmin
A continuación, como sana costumbre recomiendo cambiar la clave de root de MySQL.
mysql -u root
mysql> SET PASSWORD FOR 'root'@'localhost' = PASSWORD('yourpassword');
Y por último, si hemos instalado PHP, editar el fichero /etc/php5/apache2/php.ini y habilitar el uso de mysql, en la línea:
;extension=mysql.so Cambiadla por: 1extension=mysql.so
Apache2 se configura de modo que se le indica al servidor en que interfaces de red y puertos debe funcionar. Tomemos la imagen siguiente:

Disponemos de varios nombres de dominio (reales o ficticios) y deseamos que apunten a la misma máquina, pero claro, no queremos que apache nos facilite las mismas Webs para cada uno, sino que sean proyectos diferentes (multihost), para ello debemos indicar el sistema DNS que esos nombres apuntan a la IP del servidor de trabajo.
Si estuviéramos en un entorno real y profesional, tendríamos un servidor DNS y un servidor LAMP dedicado con una IP W.X.Y.Z, e indicaríamos al servidor DNS que cada dominio apunte al servidor con IP W.X.Y.Z. Como estamos probando en un servidor “monopuesto” no necesitamos configurar ningún servidor DNS, sólo debemos editar el fichero /etc/hosts. Este fichero es una reminiscencia del origen de Internet y contiene parejas del tipo (nombre, ip).
De modo que si queremos añadir el dominio de prueba “midominio”, sólo debemos añadir al final del fichero /etc/hosts la sighuiente línea:
127.0.0.1 midominio
Una vez hecho esto, nuestro equipo sabe que la IP del dominio midominio es 127.0.0.1. Pero, sólo nuestro equipo, este fichero es local al equipo dónde lo hemos editado de ahí que este sistema sólo nos sirva para el equipo de trabajo no para trabajar en equipo.
Y por fin, vamos a ver los pasos para configurar un sistema multihost en nuestro apache2. Supongamos que los DocumentRoot de los diferentes dominios estan en la carpeta /home/usuario/www, debemos seguir estos pasos:
$ sudo usermod -G www-data USUARIO
$ find $PWD -type d -print -exec chmod 775 {} \;
$ find $PWD -type f -print -exec chmod 664 {} \;
$ sudo chown -R USUARIO:www-data *
<VirtualHost *:80>
ServerAdmin info@miemail.com
Servername midominio
DocumentRoot /home/usuario/www/midominio
LogLevel warn
ErrorLog ${APACHE_LOG_DIR}/midominio_error.log
CustomLog ${APACHE_LOG_DIR}/midominio_access.log combined
<Directory />
Options FollowSymLinks
AllowOverride None
</Directory>
<Directory /home/usuario/www/midominio>
Options Indexes FollowSymLinks MultiViews
AllowOverride All
Order allow,deny
allow from all
</Directory>
</VirtualHost>Debemos tener cuidado con lo siguiente, en Debian/Ubuntu la configuración inicial de apache2 desactiva el uso del fichero .htaccess. Para habilitarlo debemos ser cuidadods de poner la directiva AllowOverride All como en el ejemplo anterior.
Novedad: En versiones recientes de apache está configuración puede no ser suficiente y debemos añadir alguna directiva adicional, para no encontrartos un error HTTP 403 Forbbiden. De modo que en la configuración del directorio con el DOCUMENT ROOT debemos a Require all granted, quedando algo así
:
<Directory "your directory here"> Order allow,deny Allow from all # New directive needed in Apache 2.4.3: Require all granted
Tal y como podemos leer en Stack Overflow.
$ sudo a2enmod rewrite $ sudo service apache2 restart
Suerte con vuestros servidores LAMP!
Hace poco, he tenido un pequeño “problema” instalando un servidor web apache2 y quería resolver cómo lo he solucionado. Trans instalar apache2 al realizar cualquier operación de administrador obtengo este mensaje:
* Starting web server apache2 apache2: Could not reliably determine the server's fully qualified domain name, using 127.0.1.1 for ServerName
Tranquilidad, no ocurre nada. Sólo que apache no sabe que nombre (DNS) tiene el servidor y por defecto emplea la IP de loopback (127.0.0.1). esto es así porqué httpd.conf está vacío, una solución sería añadir la cadenaServerName, pero con la nueva estructura de directorios de Apache2 disponemos de la siguiente opción:
sudo sh -c 'echo "ServerName localhost" >> /etc/apache2/conf.d/name' && sudo service apache2 restart
Con lo cual queda asignado este nombre y solucionado el problema.
¿Tienes el disco duro hasta los topes? ¿Estás pensando en borrar ficheros multimedia o viejos documentos? Pues espera, que quizás te sorprenda una forma sencilla de liberar espacio de tu distribución basada en Debian.
¿Cómo? Si tienes Debian, Ubuntu o similar su sistema de instalar programas (paquetes) se basa en la herramienta apt. Esta herramienta construye una cache durante el tiempo de vida de tu linux para funcionar y llevar el control de actualizaciones, instalaciones, y toda su gestión.
En primer lugar, si quieres saber cuánta caché tiene tu sistema apt, teclea en consola el siguiente comando:
du -sh /var/cache/apt/archives
Para liberar este espacio ejecuta:
sudo apt-get autoclean sudo apt-get clean sudo apt-get autoremove
¿Qué hace cada cosa?
sudo apt-get autoclean: Elimina del cache los paquetes .deb con versiones anteriores a los de los programas que tienes instalados.
sudo apt-get clean: Elimina todos los paquetes del cache. El único inconveniente que podría resultar es que si quieres reinstalar un paquete, tienes que volver a descargarlo.
sudo apt-get autoremove: Borra los paquetes huérfanos, o las dependencias que quedan instaladas después de haber instalado una aplicación y luego eliminarla, por lo que ya no son necesarias.
¡Espero que sea de ayuda!
Todo desarrollador WEB que se precie sabe que debe conocer (sino dominar) el protocolo de comunicación HTTP. Sobre este protocolo se basan todas las comunicaciones en la WEB (esto no es cierto del todo ;_)).
En proyectos anteriores he tenido que realizar varías consultas y envío de datos a través del API de Google usando productos como Contacts, Calendar, etc.
Ahora no voy a explicar cómo funciona el protocolo OAtuh [1], pero si diré que es el mecanismo que usa Google para permitir el acceso a sus APIs de forma segura.
Trabajar con este protocolo y manejar mensajes entre mi aplicación y los distintos servidores de Google ha requerido una depuración muy estricta a nivel HTTP y la mejor herramienta que he podido usar es CURL.
Curl [2], es una herramienta muy conocida entre los administradores de sistemas y muy extendida entre los programadores de PHP.
No quiero perderme en detalles, pero vamos ver un ejemplo donde se realiza una petición a un script PHP que contiene el código:
Este código realiza una redirección a http://www.google.com, pero la pregunta es: Entre mi navegador Web y el servidor, ¿qué mensajes HTTP se transmiten? Si utilizamos la opción -v (verbose) podemos ver los mensajes de información del programa (precedidos por *), los mensajes que se envían al servidor (>) y los mensajes que se reciben del servidor (<).
$ curl -v http://webserver/header_location.php * About to connect() to webserver port 80 (#0) * Trying 172.x.y.z... connected * Connected to webserver (172.x.y.z) port 80 (#0) > GET /header_location.php HTTP/1.1 > User-Agent: curl/7.18.0 (i486-pc-linux-gnu) libcurl/7.18.0 OpenSSL/0.9.8g zlib/1.2.3.3 libidn/1.1 > Host: webserver > Accept: */* > < HTTP/1.1 302 Found < Date: Mon, 04 Nov 2013 17:07:30 GMT < Server: Apache/2.2.8 (Ubuntu) DAV/2 SVN/1.4.6 PHP/5.2.4-2ubuntu5.27 with Suhosin-Patch mod_ssl/2.2.8 OpenSSL/0.9.8g < X-Powered-By: PHP/5.2.4-2ubuntu5.27 < Location: http://www.google.com/ < Content-Length: 0 < Content-Type: text/html < * Connection #0 to host webserver left intact * Closing connection #0
Bueno, ahora sabemos que este script/página nos envía a google, pero … ¿se puede automatizar el proceso para ver todos los mensajes HTTP hasta que se sirve la página WEB? Sí, usando la opción -L.
Usando un comando cómo:
$ curl -v -L http://webserver/header_location.php